Digital you
Humanity is being digitized, and medicine will never be the same again. A spittle now gets you 1.5GB of genomic data, while your $80 watch captures your heart, exercise and sleep patterns 24/7.
Annual checkups suddenly seem quaint.
Humanity in hi-def looks qualitatively different. A pill, once thought to be ‘20% effective’, is understood to be 100% effective for people with a certain genotype (found in 20% of the population), and useless for everyone else. With so many unique data points, the days when ‘recommended dosage’ distinguishes only two kinds of humans – ‘Children Under 12’ and ‘Adults 12 and Older’ – are drawing to a close.
“In the next 10 years, data science and software will do more for medicine than all of the biological sciences together” (Vinod Khosla)
The digitization of humanity brings the promise of precision medicine . Can it also deliver precision underwriting?
100x digital zoom
Genomics and wearables are directly relevant to life and health insurance, but the digitization of humanity is a helpful metaphor for insurance more broadly.
A standard homeowners’ policy is based on a form with 20–40 fields (name, address, birthday…); so 20–40 data points are what a traditional insurer collects per customer.
It’s different for companies built on a digital substrate. Lemonade’s chatbots do away with forms altogether, making the process fast and fun, but the data implications are still more profound:
Lemonade collects about 100x more data-points per customer.
That’s the power of an entirely digital experience.
Digital divination
It took 10 years after the genome was sequenced for deep insights to emerge. You see, collecting genetic data isn’t helpful per se. What’s helpful is finding connections between genes and real-world outcomes throughout our lifecycle. That takes time.
Digital insurers are embarking down the same road. Collecting orders of magnitude more data isn’t the goal ; correlating them with real-world claims is.
In the 20 months since its launch, Lemonade’s business grew exponentially. After a natural lag, claims data are now growing at the same rate, and have reached a level where previously undiscovered patterns are coming into focus.
Much like genetic data did for the ‘20% effective’ pill, these data have already uncovered several instances where a population that appears to be monolithic (at a resolution of 40 data points), is revealed to be a composite (when the resolution is increased by two orders of magnitude). These subgroups exhibit a 3x difference in their losses, with far reaching implications for the future of insurance.
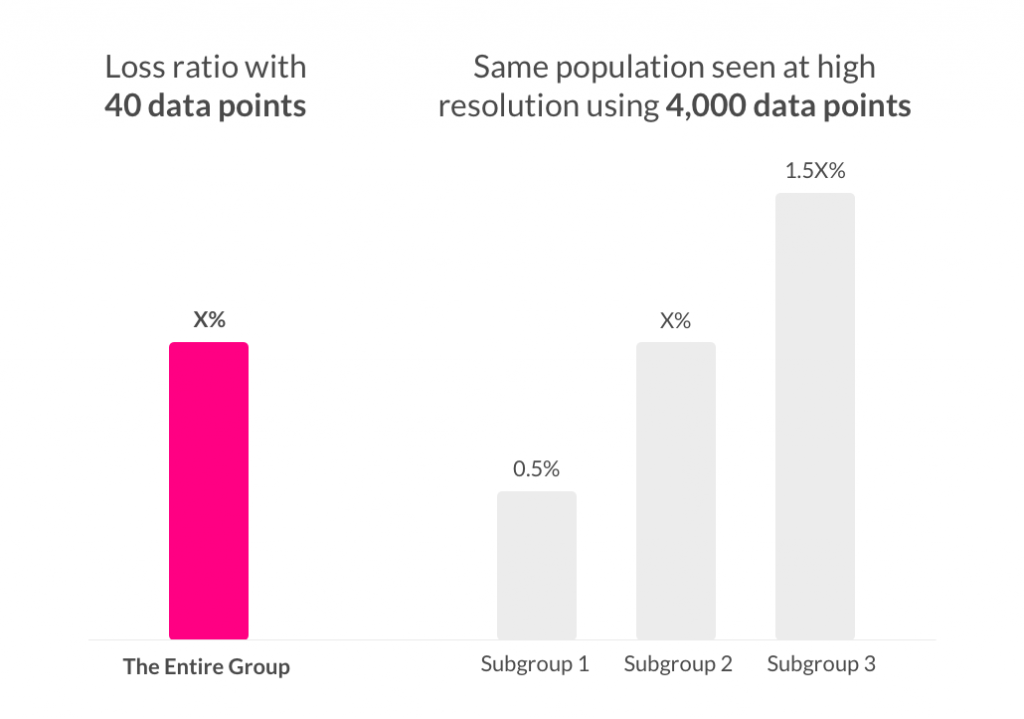
These aren’t one-offs. As data accumulates, a recursive pattern emerges. Groups thought to be uniform are exposed as comprised of sub-groups. Under the weight of the data, these subgroups give up their own component-groups, and so on, enabling ever more precise underwriting.

Traditional insurers, with over a century of accumulated data each, still enjoy a data advantage over newcomers. But being digital natives, the neophytes have a structural advantage, and their penchant for growth and data is fast eroding the incumbents’ lead. It may be erased within the next 18–24 months.
N=1:
Much like the traditional insurance form, the blood-panel of yore yields 20–40 data points. Whether in medicine or insurance, at this resolution millions of people look very much alike. N=millions.
Being able to see people digitally increases this resolution by orders of magnitude. Instead of a pixelated outline of a human, you get a high resolution image of an individual. N=1.
N=1 is the secret of precision medicine, and it is the promise of precision underwriting.
Next 10 years
It’s early days. The machine is in the embryonic stage of data gathering, and only the most crude correlates have been uncovered so far. But the flywheel is gaining momentum, and it’s not hard to imagine how the next decade will play out:
Bring it.